JVM概述(一)
首先我们要了解虚拟机的具体定义,我们所接触过的虚拟机有安装操作系统的虚拟机,也有我们的Java虚拟机,而它们所面向的对象不同,Java虚拟机只是面向单一应用程序的虚拟机,但是它和我们接触的系统级虚拟机一样,我们也可以为其分配实际的硬件资源,比如最大内存大小等。
并且Java虚拟机并没有采用传统的PC架构,比如现在的HotSpot虚拟机,实际上采用的是基于栈的指令集架构,而我们的传统程序设计一般都是基于基于寄存器的指令集架构,这里我们需要回顾一下计算机组成原理中的CPU结构:
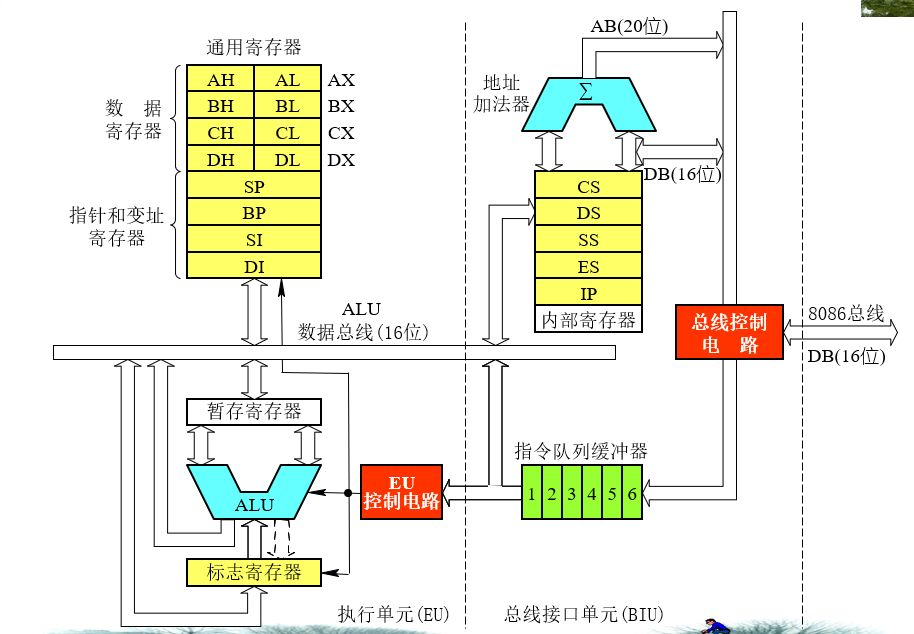
其中,AX,BX,CX,DX 称作为数据寄存器:
- AX (Accumulator):累加寄存器,也称之为累加器;
- BX (Base):基地址寄存器;
- CX (Count):计数器寄存器;
- DX (Data):数据寄存器;
这些寄存器可以用来传送数据和暂存数据,并且它们还可以细分为一个8位的高位寄存器和一个8位的地位寄存器,除了这些通用功能,它们各自也有自己的一些专属职责,比如AX就是一个专用于累加的寄存器,用的也比较多。
SP 和 BP 又称作为指针寄存器:
- SP (Stack Pointer):堆栈指针寄存器,与SS配合使用,用于访问栈顶;
- BP (Base Pointer):基指针寄存器,可用作SS的一个相对基址位置,用它可直接存取堆栈中的数据;
SI 和 DI 又称作为变址寄存器:
- SI (Source Index):源变址寄存器;
- DI (Destination Index):目的变址寄存器;
主要用于存放存储单元在段内的偏移量,用它们可实现多种存储器操作数的寻址方式,为以不同的地址形式访问存储单元提供方便。
控制寄存器:
- IP (Instruction Pointer):指令指针寄存器;
- FLAG:标志寄存器;
段寄存器: - CS (Code Segment):代码段寄存器;
- DS (Data Segment):数据段寄存器;
- SS (Stack Segment):堆栈段寄存器;
- ES (Extra Segment):附加段寄存器;
这里我们分别比较一下在x86架构下C语言和arm架构下编译之后的汇编指令不同之处:
1 | int main() { |
1 | .file "main.c" |
在arm架构下(Apple M1 Pro芯片)编译的结果为:
1 | .section __TEXT,__text,regular,pure_instructions |
我们发现,在不同的CPU架构下,实际上得到的汇编代码也不一样,并且在arm架构下并没有和x86架构一样的寄存器机构,因此只能使用不同的汇编指令操作来实现。
所以这也是为什么C语言不支持跨平台的原因,我们只能将同样的代码在不同的平台上编译之后才能在对应的平台上运行我们的程序。而Java利用了JVM,它提供了很好的平台无关性(当然,JVM本身是不跨平台的),我们的Java程序编译之后,并不是可以由平台直接运行的程序,而是由JVM运行,同时,我们前面说了,JVM(如HotSpot虚拟机),实际上采用的是基于栈的指令集架构,它并没有依赖于寄存器,而是更多的利用操作栈来完成,这样不仅设计和实现起来更简单,并且也能够更加方便地实现跨平台,不太依赖于硬件的支持。
这里我们对一个类进行反编译查看:
1 | public class Main { |
1 | javap -v target/classes/com/test/Main.class #使用javap命令对class文件进行反编译 |
1 | public int test(); |
我们可以看到,java文件编译之后,也会生成类似于C语言那样的汇编指令,但是这些命令都是交给JVM去执行的命令(实际上虚拟机提供了一个类似于物理机的运行环境,也有程序计数器之类的东西),最下方存放的是本地变量(局部变量)表,表示此方法中出现的本地变量,实际上this也在其中,所以我们才能在非静态方法中使用this关键字,在最上方标记了方法的返回值类型、访问权限等。首先介绍一下例子中出现的命令代表什么意思:
- bipush 将单字节的常量值推到栈顶
- istore_1 将栈顶的int类型数值存入到第二个本地变量
- istore_2 将栈顶的int类型数值存入到第三个本地变量
- istore_3 将栈顶的int类型数值存入到第四个本地变量
- iload_1 将第二个本地变量推向栈顶
- iload_2 将第三个本地变量推向栈顶
- iload_3 将第四个本地变量推向栈顶
- iadd 将栈顶的两个int类型变量相加,并将结果压入栈顶
- ireturn 方法的返回操作
有关详细的指令介绍列表可以参考《深入理解Java虚拟机 第三版》附录C。
JVM运行字节码时,所有的操作基本都是围绕两种数据结构,一种是堆栈(本质是栈结构),还有一种是队列,如果JVM执行某条指令时,该指令需要对数据进行操作,那么被操作的数据在指令执行前,必须要压到堆栈上,JVM会自动将栈顶数据作为操作数。如果堆栈上的数据需要暂时保持起来时,那么它就会被存储到局部变量队列上。
我们从第一条指令来依次向下解读,显示方法相关属性:
1 | descriptor: ()I //参数以及返回值类型,()I就表示没有形式参数,返回值为基本类型int |
有关descriptor的详细属性介绍,我们会放在之后的类结构中进行讲解。
接着我们来看指令:
1 | 0: bipush 10 //0是程序偏移地址,然后是指令,最后是操作数 |
这一步操作实际上就是使用bipush将10推向栈顶,接着使用istore_1将当前栈顶数据存放到第二个局部变量中,也就是a,所以这一步执行的是int a = 10操作。
1 | 3: bipush 20 |
同上,这里执行的是int b = 20操作。
1 | 6: iload_1 |
这里是将第二和第三个局部变量放到栈中,也就是取a和b的值到栈中,最后iadd操作将栈中的两个值相加,结果依然放在栈顶。
1 | 9: istore_3 |
将栈顶数据存放到第四个局部变量中,也就是c,执行的是int c = 30,最后取出c的值放入栈顶,使用ireturn返回栈顶值,也就是方法的返回值。
至此,方法执行完毕。
实际上我们发现,JVM执行的命令基本都是入栈出栈等,而且大部分指令都是没有操作数的,传统的汇编指令有一操作数、二操作数甚至三操作数的指令,相比C编译出来的汇编指令,执行起来会更加复杂,实现某个功能的指令条数也会更多,所以Java的执行效率实际上是不如C/C++的,虽然能够很方便地实现跨平台,但是性能上大打折扣,所以在性能要求比较苛刻的Android上,采用的是定制版的JVM,并且是基于寄存器的指令集架构。在某些情况下,我们可以使用JNI机制来通过Java调用C/C++编写的程序以提升性能(也就是本地方法,使用到native关键字)
B站「青空の霞光」
《深入理解Java虚拟机》

